Reading Google Sheets data using Python
Google docs are one of the widely used tools across the industry and the spreadsheets are used to store lot of our data, which we would want to access anytime for data analysis or any other purpose. Check my previous posts where I have talked about analyzing & visualizing the data using google spreadsheets.
Many a times there is a need to access this data at the run time and there are different ways you can access these data from the google spreadsheet, onw way by using Google API’s, which requires you to Turn on google sheets API, install google client library, Authentication and then write a script to access the data. This is a wonderful and a secure way to access the data from the drive.
However I was looking for a much simpler way to access the data Per say in a Pythonic way, within 2-3 lines of code and which can be easily consumed by the Pandas Dataframe and can help me for further data analysis and I do not have to spend much time writing the script for accessing the google spreadsheet.
In this post we will see how Python Requests and Pandas Dataframe can be used in conjunction to pull the data from the Google spreadsheet and will be consumed directly into Pandas dataframe.
Pandas is an open source and fast & easy high performance data analysis library which is developed by Wes Mckinney. you can find more details on it’s official page here. Pandas has two types of data structures Series & Dataframe, Series is like one dimensional objects like an array list and Dataframe is a two-dimensional spreadsheet structure having rows & columns. We are going to use Dataframes for this post.
Requests is a simple to use HTTP library for python, which we would be using to scrape the content of our google spreadsheet.
Dataset to be used for this post is Booker Prize winners list from Wikipedia:
https://en.wikipedia.org/wiki/Booker_Prize
Check my previous posts here on how to import data from web in google spreadsheet in one simple step.
Once you have the data from the wikipedia link in your google spreadsheet, Save it on your drive and then navigate to the following menu File > Publish to the Web and select Comma-Separated values(.csv) and copy the link.

Now using Python requests we will write a simple two line of code to get this data in pandas data frame:
import pandas as pd #Paste copied link here pathtoCsv = r'https://docs.google.com/spreadsheets/d/12mrYK9ouCRLq6tPje8p4XJIM9ceotAEZJZpXhLa6-uc/pub?output=csv' df = pd.read_csv(pathtoCsv, encoding = 'utf8')
The data is now consumed in the pandas dataframe(df) and can be used for further analysis. Let’s see how to explore the data using dataframe.
I’m using ipython notebook for analysis but you can do this exercise in any editor of your choice.
Let’s find out the info about the dataframe: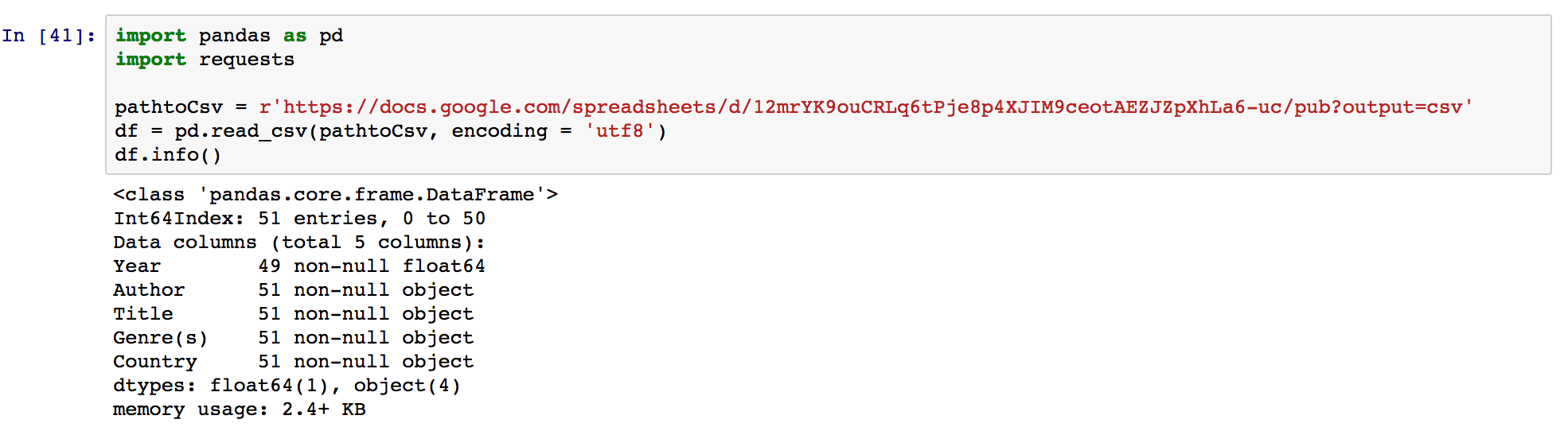
There are total 5 columns and 51 rows in this dataset and you can also check the datatype for each column as well.
Basic Analysis using Pandas Dataframe:
- Find out number of Authors from India who won Bookers Prize using this dataset
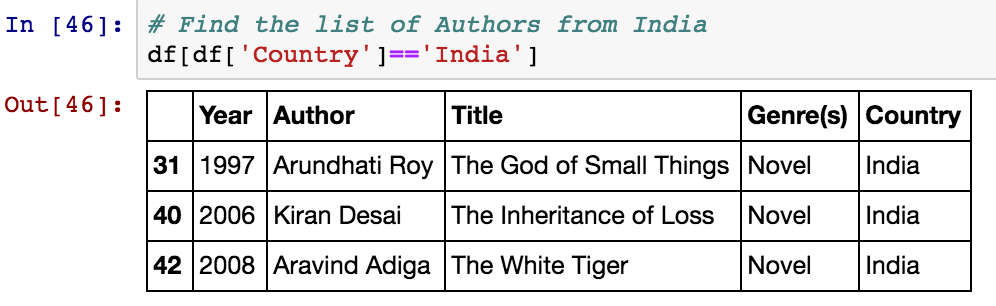
- Find out the count of Authors from each country
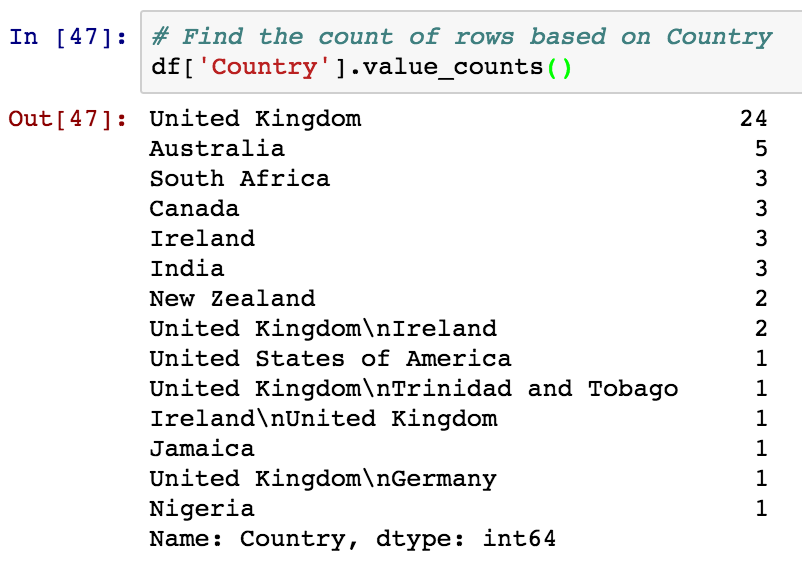
United Kingdom has topped the list, Followed by Australia and South Africa. We can further use this dataframe api’s and function in conjunction with plotting libraries to plot the graphs and visualize the dataset.

