Time Series Data Visualization
Visualizing Time Series data with Python
In this post we will discuss data exploration techniques of time series data sets. We will discuss how plotting, histograms and other methods to visualize the time series data can be applied
Graphical Analysis of Time Series data is an important step of time series analysis and helps to provides an insight on the data and understand what data is telling us
Data visualization is a crucial step and should be the first step before starting with time series modelling
it’s important to know before modelling that how the variables are correlated, what are the value ranges and how it is effected by the time period. Is the data is consistent and uniform and many more aspects of a data can be learnt using Graphical analysis
Dataset
For this post we are going to use the Airline Passenger data from this Kaggle link:
Data Download Link: https://www.kaggle.com/rakannimer/air-passengers
This data set contains monthly count of passengers for an airline from year 1949 thru 1957
We will load the dataset in a pandas dataframe and convert the Months column to a datettime object and will rename the column #Passenger to Passenger
import pandas as pd
df = pd.read\_csv('./AirPassengers.csv')
df['Month'] = pd.to_datetime(df['Month'])
df.columns = ['Month','Passenger']
df.head()
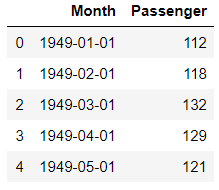
This dataset is nicely formatted and sampled and is in a much better shape. We don’t have to worry about missing values, Non discrete data and Outlier detection.
Time Series Analysis with Line Plot
Our first step to visualize this dataset is same as any other dataset i.e. to plot a simple line plot
This is a univariate data so we will have Month on X-axis and Number of Passengers on Y-Axis. We can also choose the linestyle, marker color for each data points and marker size as well
We will rename the x and y axis label as Year and Passenger
df.plot(x='Month',y='Passenger',figsize=(15,6),linestyle='--', marker='*', markerfacecolor='r',color='y',markersize=10)
plt.xlabel('Years')
plt.ylabel('Passengers')
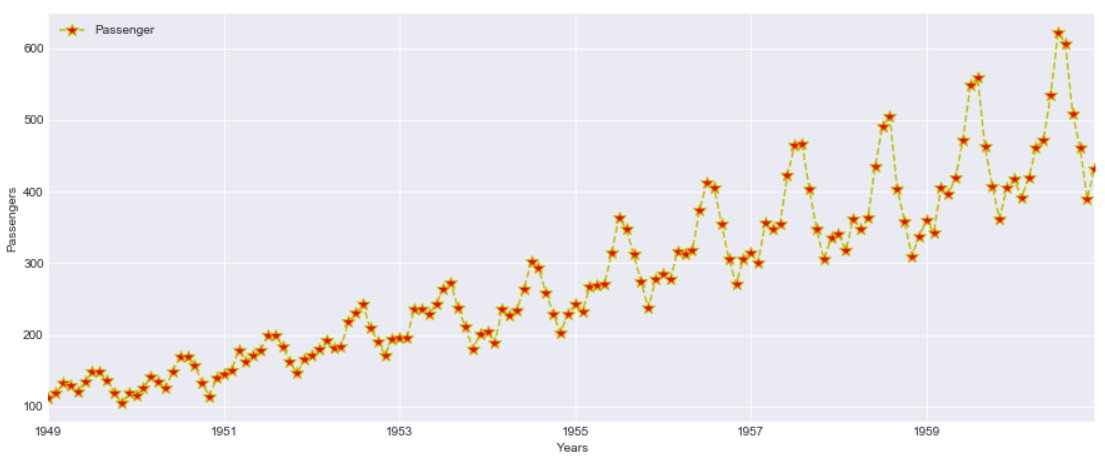
This plot is quite informative and we can see an upward trend here. With every passing years the passenger count is increasing and there is a seasonality in data also
What is Seasonality? Every year the passenger counts increases for a month and then goes down again and same effect is repeated every year
Let’s continue our Exploratory Analysis and we will resample this data Quarterly i.e. 3 months and then visualize it on a Quarterly data plot
df1 =df.set_index('Month').resample('3M').mean()
df1.head()
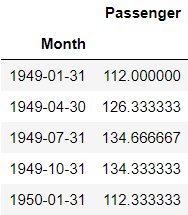
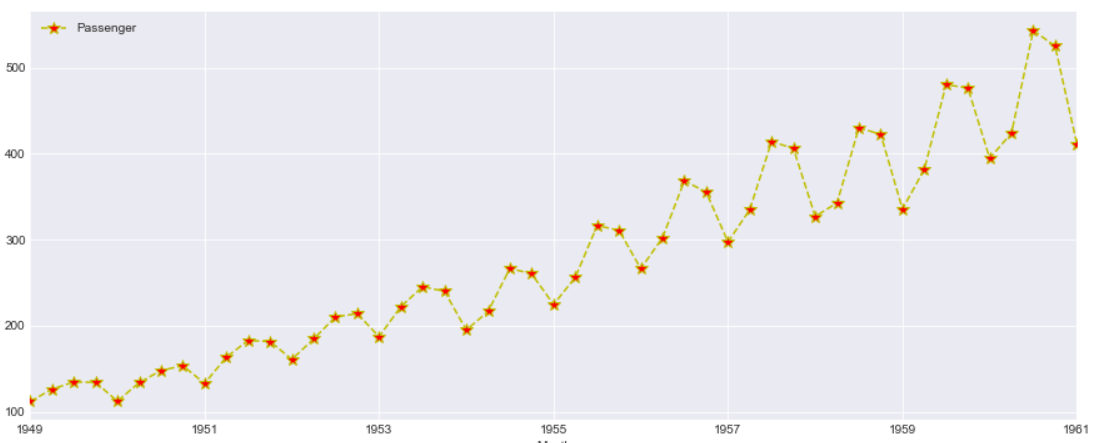
This looks more clear and the Quarterly data points i.e. Red markers are visible for each year. However the trend and Seasonality in the data is same as seen above
Scatter Matrix
A Scatter plot in time series is as important than with any other data. Here we are plotting the difference between adjacent time points using Pandas diff() function and plotted a diff plot between passenger and GDP
df.diff().plot(figsize=(20,6),kind='scatter',x = 'GDP', y = 'Passenger',color='black')
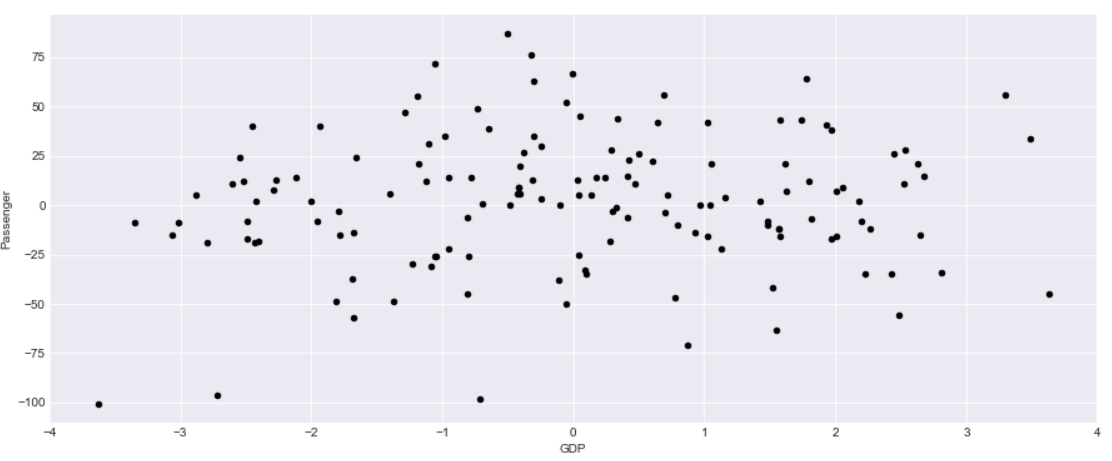
This data looks bit informative and we can see there is a correlation with GDP and Passenger count. So what we are interested to find out here is How a change in GDP will impact the Passengers travelling in airplanes
Another Aspect of this graph is the negative change in GDP also sees some surge in Passenger count so there is a correlation but the relationship are not as strong.
Can we forecast the passenger count based on the change in GDP?
Time Series Lag Plot
A lag plot helps to check if a time series data set is random or not. A random data will be evenly spread whereas a shape or trend indicates the data is not random.
It is a scatter plot where one data point is plotted against the other with a fixed amount of lag. So a first order lag plot is using a lag of 1
For plotting lag chart we can use Pandas lag_plot() function. The x-axis contains y(t) and y-axis contains the data point after 1 lag point i.e. y(t+1)
pd.plotting.lag_plot(df['Passenger'])
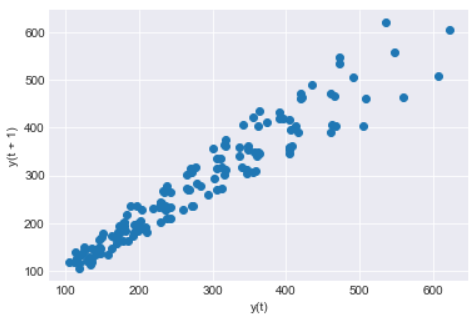
So we can see a linear trend in our data and the data set is not Random. There is no outliers as such also detected in this data set
Lag can also be useful to identify the suitable time series model for the data. So looking at this linear trend for our data a Auto Regressive model will be good
Heatmap and Hexbin Plot
We will make a 2D histogram or a density heatmap using matplotlib hist2d() function with Year on X-axis and Number of Passengers on Y-axis
x=df['Year']
y=df['Passenger']
plt.hist2d(x, y)
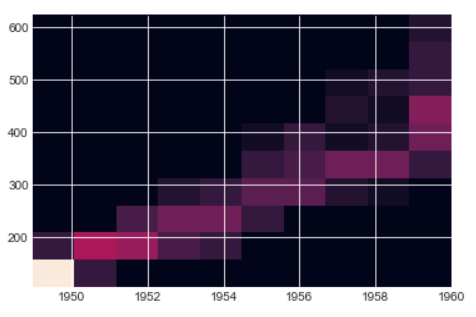
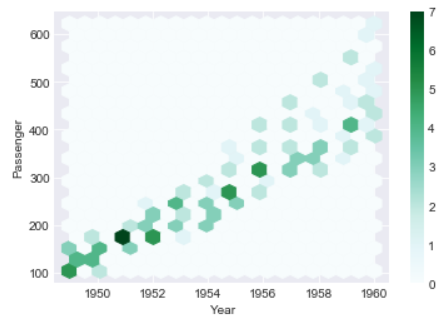
The below hexbin plot looks better than the heatmap and the trend is also quite evident from this hexbin too. You can see growing Passengers with every year
In both heatmap above and hexbin below the count of passenger are colored and shows the number of passengers for each Year
ax = df.plot.hexbin(x='Year', y='Passenger', gridsize=20)
3D Visualization of Time Series Plot
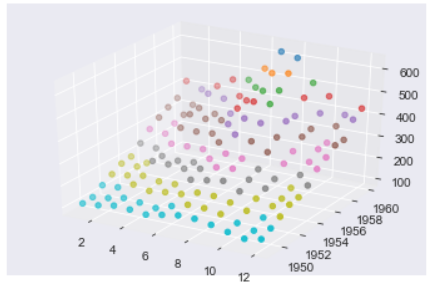
Let’s create two additional columns i.e. Month and Year. We will extract the values of these columns from the Month column
df['Month_name']=df['Month'].dt.month
df['Year']=df['Month'].dt.year
df.head()
This is how our new dataframe looks like with two additional columns for Month and Year
We will plot a 3-Dimension plot of our data using two datetime dimension i.e. X-axis is Month Name and Y-axis is Year and third dimension Z-axis is Number of Passengers
This Graph doesn’t show any extra insight than 2D graph seen before but a 3D Visualization gives much more better shape than a 2D graph because of data paucity and randomness
from mpl_toolkits import mplot3d
ax = plt.axes(projection='3d')
# Data for three-dimensional scattered points
ydata = df['Year']
xdata = df['Month_name']
zdata = df['Passenger']
ax.scatter3D(xdata, ydata, zdata, c=zdata, cmap='Vega10_r');
Moving Average and Exponential Weighted Moving Average (EWMA)
Moving Average(MA) and Exponential Weighted Moving Average(EWMA) is a rolling window function and is very critical steps for time series analysis which is used to aggregate the data and compress it.
These functions are used to smooth the data to remove outliers and noise from the data and allowing the patterns and trends in data more visible and standout. It will smooth out short-term fluctuations and highlight longer-term trends or cycles
Moving Average is calculated by taking the mean of set of data within a fixed window size in a data set. The window size can start from 2 onwards
Let’s calculate the moving average of Passenger column in our dataset with a window size of 3 . We will calculate the average of the passengers count for every 3 months and store it in a new column called Rolling Mean
Pandas has a rolling() function to calculate the rolling mean of a dataframe or Series
df['rolling_mean']=df['Passenger'].rolling(12).mean()
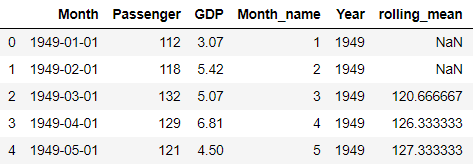
The first two values of rolling_mean Column is NaN because the window size is set to 3 so it will start by calculating the mean of first 3 months of 1949 i.e. Row # 0,1 and 2 and then Row# 1,2 and 3
Exponential Smoothing(EWMA) unlike moving average which doesn’t treat all the data points equally while smoothing. Most of the time in a Time series data we want to treat the most recent data with more weight than the previous data
n EWMA we are weighting the more recent points higher than the lags or lesser recent points. You can read more about smoothing and EWMA in this post
Let’s Calculate the EWMA for our data using Pandas ewm() function with a smoothing level of 0.6. You can try with different alpha levels and check the output and use the most appropriate alpha level for your data
df['EWM_ALPHA_06'] = df['Passenger'].ewm(alpha=0.2).mean()
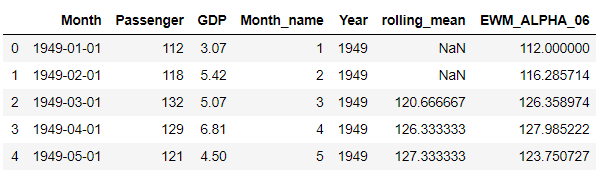
Now let’s plot these two Columns rolling means and EWMA with the original data and check how does the new smoothed values look like
df.reset_index().plot(figsize=(15,6),kind='line',x = 'index', y = 'Passenger')
plt.grid(True)
plt.plot(df['rolling_mean'],label='roll_mean',color='r')
plt.plot(df['EWM_ALPHA_06'],label='ewma',color='g')
plt.legend(loc=2)
plt.show()
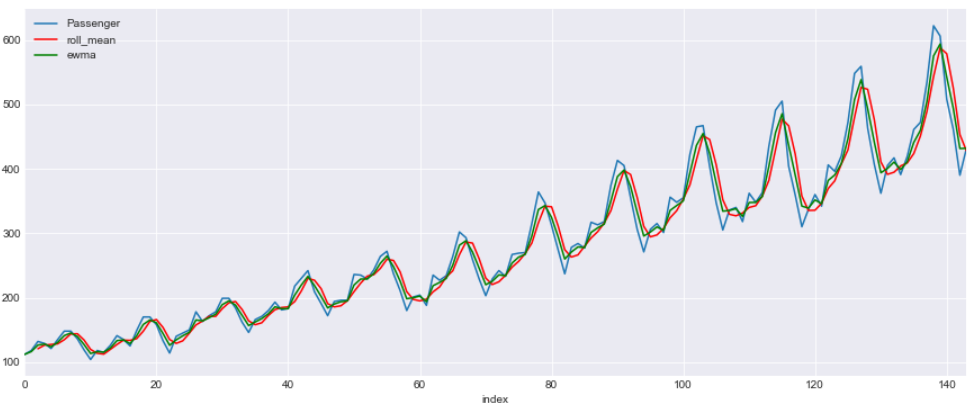
This is a line graph with three lines. Blue line shows the original data and red is for rolling mean with a window of 3 and green is for EWMA with a alpha 0.6
Box and Whisker Plot
We will draw a box plot grouped by Year to visualize the data distribution for Passenger count by Year .
The whiskers at the end of each box shows the Inter-Quartile Range and any data point above or below this whiskers are considered as an outlier
You can read more about Inter-Quartile Range and Whiskers in this post
df.boxplot(figsize=(15,6),by='Year',column='Passenger')
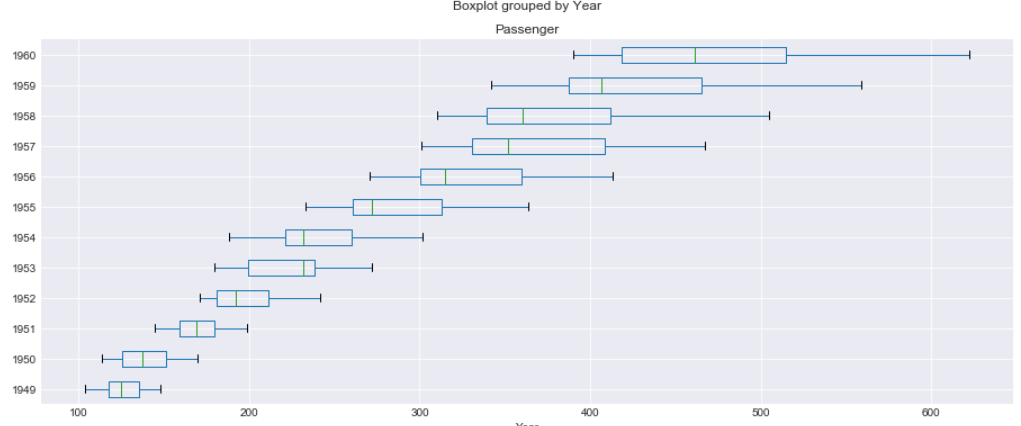
Seasonality and Trends
Now we will check the Seasonality and Trend in data. In a time series , variations which occurs due to some factors (maybe natural) and operate in a regular and periodic manner over a span of less than or equal to one year is called as Seasonality
Whereas Trend in a time series shows an increasing, decreasing trend in the data over a long period of time
For Time Series modelling the trend and Seasonality should be eliminated from the data before hand. There are models like SARIMA which can handle Seasonality in the data but most of the models doesn’t
Per Year Month on Month Count
In this plot we will have Month on the X-axis and Passenger count on the Y-axis and plot a line graph for each of the year . Every year the passenger surge can be seen for July and August and drop in demand in December and again surge during Christmas and New Year
This graphs shows us more about the Seasonality in the data
fig, ax = plt.subplots(figsize=(15,6))
for name, group in df[:60].groupby('Year'):
group.plot(x='Month_name',y='Passenger', ax=ax, label=name)
plt.show()
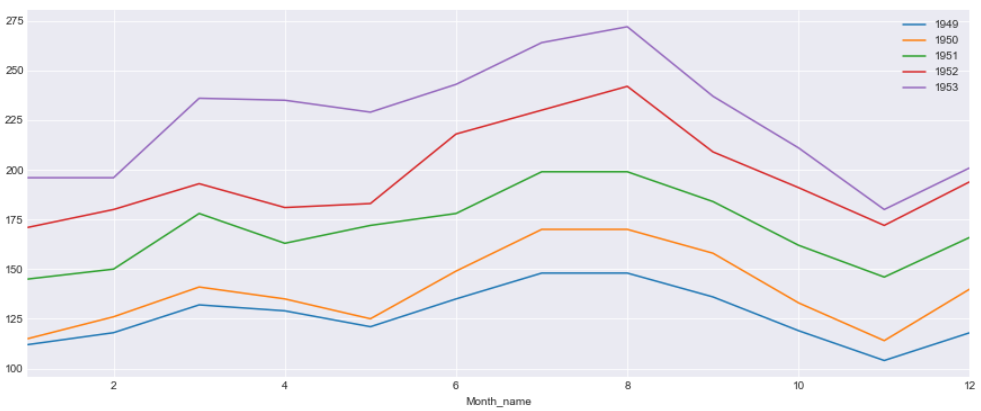
Per Month of Years on Years Plot
In this plot we will have Years on X-axis and Passenger count for each Month on Y-axis. We can see very year there is an increasing trend of passengers. The line for two months i.e. July and August shows more faster growth rate than the other months
fig, ax = plt.subplots(figsize=(15,6))
for name, group in df[:120].groupby('Month_name'):
group.plot(x='Year',y='Passenger', ax=ax, label=name,title='Plot by Month')
plt.show()
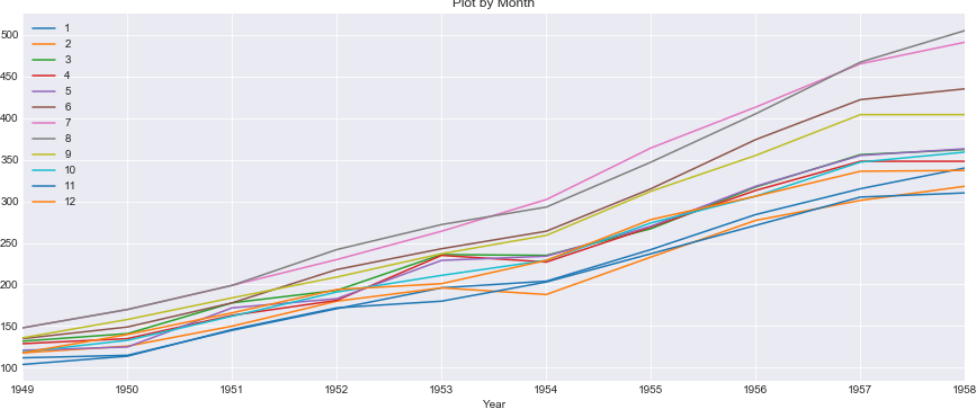
There are lot of useful information about the Seasonality and Trend of the data that can be learnt from this stack time series data than normal linear plotting of the data
Autocorrelation(ACF) and PACF
We can learn some important properties of our time series data with the help of Auto Correlation(ACF) and Partial Auto Correlation (PACF) graphs. This provide useful descriptive properties for understanding which model can be used for time series forecasting
ACF measures the linear relationships between observations at different time lags. In other words ACF is used to understand if there exists a correlation between a time series data point with another point as a function of their time difference
ACF is also called as Correlogram and a Correlogram for a Stationary process is used to Interpret Random Series, Short term correlation and Alternation Series
We will be using statsmodel Graphics API’s to plot the correlation graphs. It basically uses the matplotlib cross-correlation (xcorr) and auto correlation(acorr) under the hood. Check this matplotlib documenation
We have total 20 lags on X-axis and auto Correlation on the Y-axis and the line at Y=0 is the mean. All the correlation values are above the mean and a positive value
import statsmodels.api as sm
sm.graphics.tsa.plot_acf(df.Passenger)
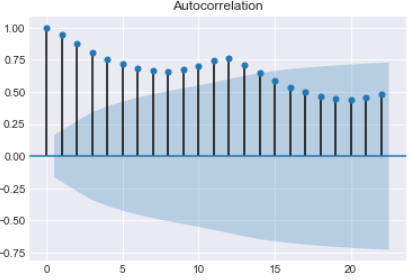
The Partial Auto Correlation factor(PACF) is the partial correlation between the two points at a specific lag of time. plotting the partial autocorrelative functions one could determine the appropriate lags p in an AR (p) model or in an extended ARIMA (p,d,q) model
For an Autoregressive AR (p) process, the partial autocorrelation(pacf) function is defined as the value of the last coefficient(alpha-p)
We will use the statsmodel graphical tools for plotting the pacf plot here
This gives an indication of Stationary time series with most of the auto correlation is above or below the mean
import statsmodels.api as sm
sm.graphics.tsa.plot_pacf(df.Passenger)
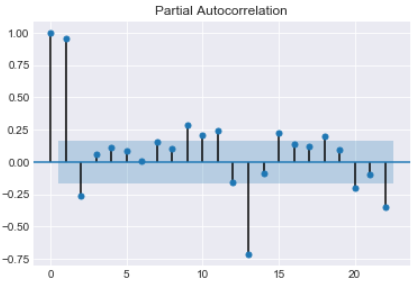
PACF shows which data points are informative for specific lags and provides a contrast to the ACF
Conclusion
So we have reached at the end of this long article and just to summarize the points that we discussed in this post
- Data Visualization is an important step for any forecasting and modelling of time series data
- Line Plot shows how the data on graph with time on X-axis. it’s helpful to see how data is distributed and the underline trend
- Scatter Plot between multivariate data shows how the two variables are correlated and relationship with adjacent time points difference
- To check the randomness of data why a Lag plot is important
- Heatmap and Hexbin to check the density of the Passenger countfor each year
- Three dimensional visualization of the time series features with two dimensions for Year and Month and third dimension for Passenger Count
- Data smoothing to eliminate the noise from the data using Rolling Winsodows and Exponential Weighted Moving Average(EWMA)
- Unlike Moving Average, EWMA gives higher weight to the most recent data point than the less recent ones
- Box and Whisker plot to determine the five point summary of passenger count for each year
- To Visualize the seasonality and trend in data a Month on Month and Year on Year graph is plotted
- AutoCorrelation (ACF) tells how data points at different point of times are related to one another
- Partial Auto Correlation(PACF) provides a contrast over ACF and shows data point that are more informative in a shorter time period
What’s Next
Read about Time Series Modelling and Forecasting with ARIMA in the next part of this blog here
Jupyter Notebook Github Link: https://github.com/min2bro/Time_Series_ARIMA/blob/master/TimeSeries%20Data%20Visualization.ipynb